Podstawy programowania
Przetwarzanie danych
© Łukasz Wawrowski
Rozpoczynanie pracy z R
Nowy projekt
- Otwórz RStudio
- Stwórz nowy projekt
- Przenieś dane do folderu projektu
- Otwórz nowy skrypt R
- (Zainstaluj i) wczytaj biblioteki
- Wczytaj dane
- Analizuj
Istniejący projekt
- Otwórz RStudio
- Otwórz istniejący skrypt R
- Wczytaj biblioteki
- Wczytaj dane
- Kontyuuj analizę
Zadanie
Wczytaj zbiór danych dotyczący wyników wyborów.
02:00
Pytania do zbioru danych
Ile obwodów głosowania miało frekwencję powyżej 80%?
Ile obwodów głosowania znajduje się w Poznaniu?
Jaka była średnia frekwencja w województwach?
Gdzie była największa różnica pomiędzy wybranymi partiami?
W jakich miastach za granicą utworzono najwięcej obwodów głosowania?
R base vs. tidyverse
Podstawowe funkcje R
widest_petals <- by(iris, INDICES = iris$Species, FUN = function(x){ x[x$Petal.Width == max(x$Petal.Width), ] })do.call(rbind, widest_petals)R base vs. tidyverse
Podstawowe funkcje R
widest_petals <- by(iris, INDICES = iris$Species, FUN = function(x){ x[x$Petal.Width == max(x$Petal.Width), ] })do.call(rbind, widest_petals)Funkcje pakietu tidyverse
iris %>% group_by(Species) %>% filter(Petal.Width == max(Petal.Width))
Przetwarzanie potokowe
Sekwencja zdarzeń - w życiu
obudź się %>% wyjdź z łóżka %>% skorzystaj z łazienki %>% zjedź śniadanie %>% ubierz się %>% idź do pracyPrzetwarzanie potokowe
Użycie operatora pipe: %>% (łącznik) ułatwia zarządzanie kodem i pisanie czytelnej składni poprzez wykorzystanie istniejących struktur danych:
Nowe obiekty
iris_3kol <- select(iris, Petal.Length, Petal.Width, Species)iris_3kol_wymiar <- mutate(iris_3kol, petal_wymiar=Petal.Length+Petal.Width)iris_3kol_wymiar_setosa <- filter(iris_3kol_wymiar, Species=="setosa")Przetwarzanie potokowe
Użycie operatora pipe: %>% (łącznik) ułatwia zarządzanie kodem i pisanie czytelnej składni poprzez wykorzystanie istniejących struktur danych:
Nowe obiekty
iris_3kol <- select(iris, Petal.Length, Petal.Width, Species)iris_3kol_wymiar <- mutate(iris_3kol, petal_wymiar=Petal.Length+Petal.Width)iris_3kol_wymiar_setosa <- filter(iris_3kol_wymiar, Species=="setosa")Zagnieżdżanie
iris_setosa <- filter(mutate(select(iris, Petal.Length, Petal.Width, Species), petal_wymiar=Petal.Length+Petal.Width), Species=="setosa")Przetwarzanie potokowe
Przetwarzanie potokowe
iris_setosa <- iris %>% select(Petal.Length, Petal.Width, Species) %>% mutate(petal_wymiar=Petal.Length+Petal.Width) %>% filter(Species=="setosa")Przetwarzanie potokowe
Przetwarzanie potokowe
iris_setosa <- iris %>% select(Petal.Length, Petal.Width, Species) %>% mutate(petal_wymiar=Petal.Length+Petal.Width) %>% filter(Species=="setosa")Znak %>% oznacza, że jako argument wejściowy data w kolejnej funkcji zostanie wpisany wynik działania wcześniejszej funkcji.
Skrót klawiszowy: ctrl + shift + m
Wybrane funkcje
select()- wybór zmiennychfilter()- wybór obserwacjimutate()- tworzenie/modyfikacja zmiennejrename()- zmiana nazwy zmiennejcount()- zliczanie obserwacjisummarise()- podsumowania danychgroup_by()- operowanie na grupacharrange()- sortowanie
Filtrowanie - filter()
Porównywanie:
=symbol przypisania (nie jest używany w filtrowaniu)==symbol porównania (jest równe)!=symbol negacji (jest różne)>i<większe i mniejsze>=i<=większe lub równe i mniejsze lub równe
Operatory:
&- i|- lub (alternatywa)%in%- wartość ze zbioru!- negacja
Zadanie
Utwórz zbiór danych zawierający filmy, które są filmami akcji, miały swoją premierę po 2010 roku i trwały co najmniej 120 minut lub miały ocenę powyżej 8.0. Alternatywa ma dotyczyć tylko dwóch ostatnich warunków.
05:00
Braki danych
Brak danych jest oznaczany jako NA. Jest to wartość nieliczbowa i nie można jej porównywać w następujący sposób:
zmienna == NAzmienna != NAzmienna == "NA"zmienna != "NA"
tylko z wykorzystaniem funkcji is.na():
is.na(zmienna)!is.na(zmienna)
Funkcja complete.cases() służy do identyfikacji obserwacji, które nie zawierają braków danych w całym zbiorze danych.
Wybieranie kolumn - select()
Wybór kolumn, które mają się znaleźć w nowym zbiorze:
iris2 <- iris %>% select(Species, Petal.Length, Petal.Width)Które nie mają się znaleźć w nowym zbiorze:
iris2 <- iris %>% select(-Petal.Length, -Petal.Width)Które mają znaleźć się w nowym zbiorze z nową nazwą:
iris2 <- iris %>% select(gatunek=Species, Petal.Length, Petal.Width)Kolejność w przetwarzaniu potokowym
DOBRZE
iris %>% filter(Petal.Width < 0.5) %>% select(Species, Sepal.Length, Sepal.Width)## Species Sepal.Length Sepal.Width## 1 setosa 5.1 3.5## 2 setosa 4.9 3.0## 3 setosa 4.7 3.2## 4 setosa 4.6 3.1## 5 setosa 5.0 3.6## 6 setosa 5.4 3.9Kolejność w przetwarzaniu potokowym
DOBRZE
iris %>% filter(Petal.Width < 0.5) %>% select(Species, Sepal.Length, Sepal.Width)## Species Sepal.Length Sepal.Width## 1 setosa 5.1 3.5## 2 setosa 4.9 3.0## 3 setosa 4.7 3.2## 4 setosa 4.6 3.1## 5 setosa 5.0 3.6## 6 setosa 5.4 3.9ŹLE
iris %>% select(Species, Sepal.Length, Sepal.Width) %>% filter(Petal.Width < 0.5)## Error in `filter()`:## ℹ In argument: `Petal.Width < 0.5`.## Caused by error:## ! object 'Petal.Width' not foundZmiana nazwy - rename()
Zapis w konwencji rename(nowa_nazwa=stara_nazwa)
Można także wykorzystać funkcję select() - zmieniając nazwę podczas wybierania zmiennych
Funkcja rename_with() umożliwia zmianę nazw z wykorzystaniem funkcji np. zamieniając nazwy kolumn na zapisane wielkimi literami.
Nowa zmienna/modyfikacja - mutate()
iris <- iris %>% mutate(petal=Petal.Length+Petal.Width, sepal=Sepal.Length+Sepal.Width, iloraz=petal/sepal)Funkcje:
mutate_all- modyfikacja wszystkich zmiennych według podanej formułymutate_if- modyfikacja wszystkich zmiennych spełniających warunekmutate_at- modyfikacja wszystkich wskazanych zmiennych
są zastępowane przez jedną funkcję across.
Zadanie
W zbiorze dotyczącym wyborów stwórz nowe zmienne, które będą zawierały procentowy wynik komitetów.
05:00
Podsumowanie - summarise() i summarize()
iris %>% summarise(liczebnosc=n(), srednia_pl=mean(Petal.Length), mediana_sl=median(Sepal.Length))## liczebnosc srednia_pl mediana_sl## 1 150 3.758 5.8Zadanie
Ile wynosiła średnia, mediana i odchylenie standardowe wartości frekwencji?
05:00
Grupowanie - group_by()
Najlepiej działa w połączeniu z summarise():
iris %>% group_by(Species) %>% summarise(liczebnosc=n(), srednia_pl=mean(Petal.Length))## # A tibble: 3 × 3## Species liczebnosc srednia_pl## <fct> <int> <dbl>## 1 setosa 50 1.46## 2 versicolor 50 4.26## 3 virginica 50 5.55Liczebności - count()
Jeżeli chcemy tylko wyznaczyć liczebności grup to wystarczy funkcja count():
iris %>% count(Species)## Species n## 1 setosa 50## 2 versicolor 50## 3 virginica 50Sortowanie - arrange()
Sortuje podane kolumny w porządku rosnącym.
iris %>% arrange(Sepal.Length, Sepal.Width) %>% head()## Sepal.Length Sepal.Width Petal.Length Petal.Width Species## 1 4.3 3.0 1.1 0.1 setosa## 2 4.4 2.9 1.4 0.2 setosa## 3 4.4 3.0 1.3 0.2 setosa## 4 4.4 3.2 1.3 0.2 setosa## 5 4.5 2.3 1.3 0.3 setosa## 6 4.6 3.1 1.5 0.2 setosaPosortowanie w porządku malejącym wymaga użycia funkcji desc() w odniesieniu do wybranej kolumny.
Zadanie
Oblicz liczbę komisji w poszczególnych województwach oraz średnią liczbę nieważnych głosów.
05:00

Zadanie
Po wczytaniu zbioru danych gus.RData połącz ze sobą zbiory danych zawierające informacje o liczbie przedsiębiorstw na 10 tys. mieszkańców (zbiór pod_10tys), stopie bezrobocia (zbiór bezrobocie) oraz wynagrodzeniu (zbiór wyn).
10:00

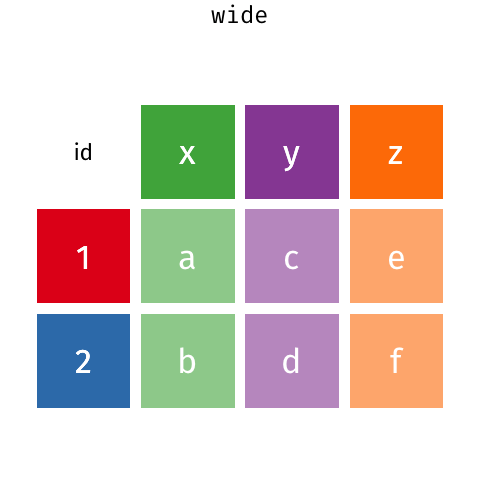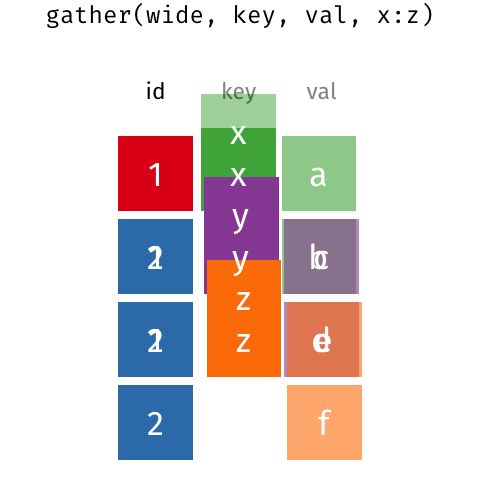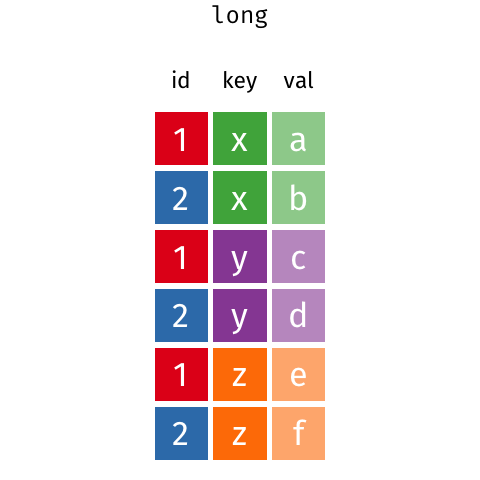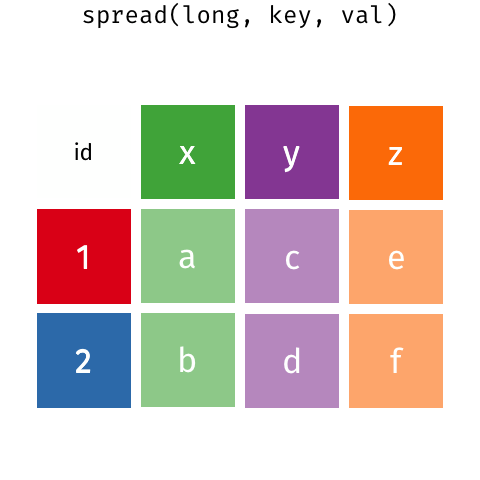
Zbiór iris
head(iris)## Sepal.Length Sepal.Width Petal.Length Petal.Width Species## 1 5.1 3.5 1.4 0.2 setosa## 2 4.9 3.0 1.4 0.2 setosa## 3 4.7 3.2 1.3 0.2 setosa## 4 4.6 3.1 1.5 0.2 setosa## 5 5.0 3.6 1.4 0.2 setosa## 6 5.4 3.9 1.7 0.4 setosaWide -> long - pivot_longer()
iris_long <- iris %>% mutate(id=1:nrow(iris)) %>% pivot_longer(Sepal.Length:Petal.Width)head(iris_long)## # A tibble: 6 × 4## Species id name value## <fct> <int> <chr> <dbl>## 1 setosa 1 Sepal.Length 5.1## 2 setosa 1 Sepal.Width 3.5## 3 setosa 1 Petal.Length 1.4## 4 setosa 1 Petal.Width 0.2## 5 setosa 2 Sepal.Length 4.9## 6 setosa 2 Sepal.Width 3Long -> wide - pivot_wider()
iris_wide <- iris_long %>% pivot_wider()head(iris_wide)## # A tibble: 6 × 6## Species id Sepal.Length Sepal.Width Petal.Length Petal.Width## <fct> <int> <dbl> <dbl> <dbl> <dbl>## 1 setosa 1 5.1 3.5 1.4 0.2## 2 setosa 2 4.9 3 1.4 0.2## 3 setosa 3 4.7 3.2 1.3 0.2## 4 setosa 4 4.6 3.1 1.5 0.2## 5 setosa 5 5 3.6 1.4 0.2## 6 setosa 6 5.4 3.9 1.7 0.4